 Edge
Edge Chrome
Chrome Firefox
Firefox一、从最简化的统计套利说起
我们假定有两个时间序列a和b,这两个序列高度相关,且价差序列a-b具有均值回归的特性,为简化起见假设均值为0,那么,我们可以观察a-b的变化,在a-b小于0时多a空b, 在a-b大于0时多b空a, 这就是最简化的统计套利模型。
为了更直观的理解,我们撸一遍代码。先构建一个随机游走的时间序列a, 起始价格为1,日波动标准差为0.01。
import numpy as np
import pandas as pd
s_random_chg=pd.Series(np.random.normal(0,0.01,1000))
s_random=(s_random_chg+1).cumprod()
s_random.plot(figsize=(10,5),grid=True);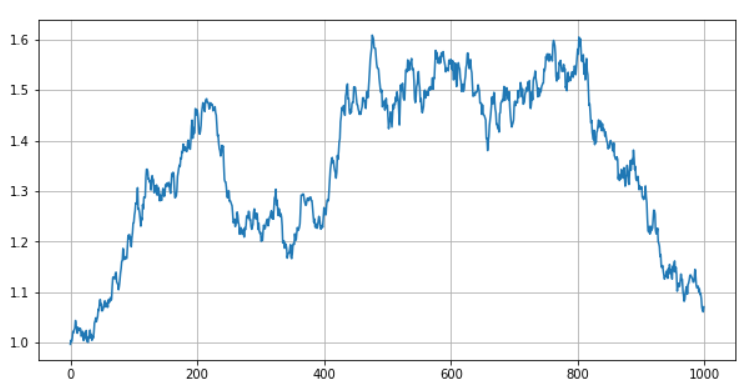
接下来,再构建一个以0为中心的均值回归序列:
def generate_reverse_serise(N):
s=0
k=0.1
s_reverse=[]
for i in range(0,N):
s=s-s*k+np.random.normal(0,0.01)
s_reverse.append(s)
return pd.Series(s_reverse)
s_reverse=generate_reverse_serise(1000)
s_reverse.plot(figsize=(10,5),grid=True);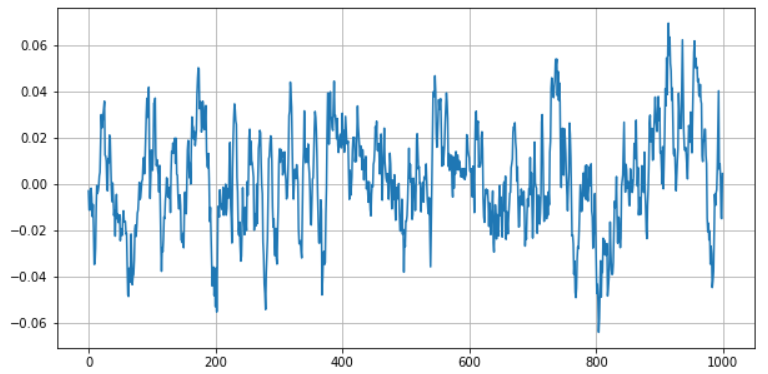
最后,把前面两个序列加起来,得到序列b。把这两个序列放一起,如下所示,我们就得到了两条高度相关的、可进行套利操作的序列。
pricedf=pd.DataFrame()
pricedf['a']=s_random
pricedf['b']=s_random+s_reverse
pricedf.plot(figsize=(10,5),grid=True);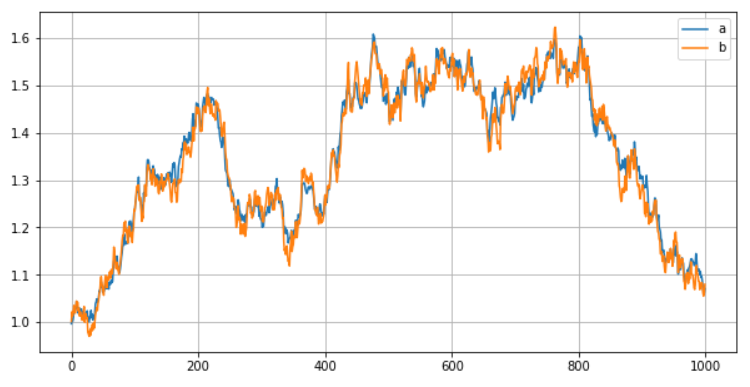
接下来,我们构建一个经典的统计套利策略,我们观察a-b价差序列,发现大部分时间在[-0.02,0.02]之间波动,我们就马后炮地选择在-0.02的时候多a空b, 在0.02的时候多b空a,在穿越零值的时候平仓。
def signal_func(c):
s=[]
flag=0
for i in range(0,len(c)):
if c[i]<-0.02:
flag=1
elif c[i]>0.02:
flag=-1
else:
if flag==1 and c[i]>0:
flag=0
elif flag==-1 and c[i]<0:
flag=0
s.append(flag)
return pd.Series(s)
signal=pd.DataFrame()
signal['a']=signal_func(pricedf['a']-pricedf['b'])
signal['b']=-signal['a']
forward_return=pricedf.pct_change().shift(-1)
pnl=(forward_return*signal).sum(axis=1)/2
(1+pnl).cumprod().plot(figsize=(10,5),grid=True);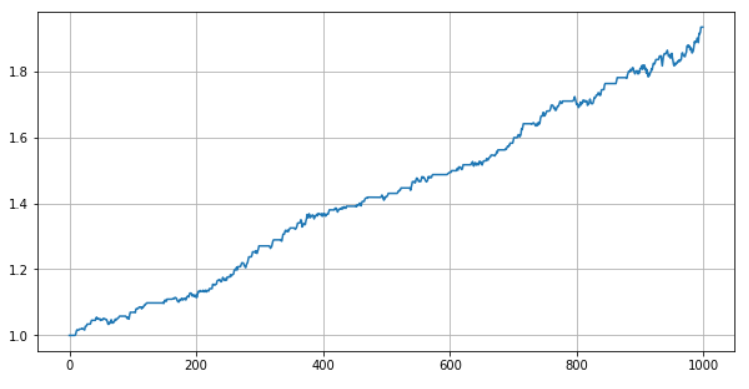
我们发现,我们的马后炮套利非常成功,净值呈45度角一路上升,感觉造个印钞机跟玩儿似的。别做梦了,这只是极度简化的理论模型,让我们往现实靠近一步,考虑更为普遍的情况,万一没有做空手段或做空成本太高呢?
二、向现实妥协的搬砖模型
现实中,收益往往需要用风险来交换,如果存在可观的价差空间,几乎可以肯定是由于无风险套利渠道不畅造成的,最常见的情况就是至少有一条腿是无法做空的。这时,我们还有个替代的模型叫搬砖。简单来说就是只做一条腿,哪个价格低就做多哪个,由于无法通过做空来对冲,需要承受标的价格下跌的风险。
我们来看看搬砖模型的表现:
signal2=signal[signal>0]
forward_return=pricedf.pct_change().shift(-1)
pnl=(forward_return*signal2).sum(axis=1)
(1+pnl).cumprod().plot(figsize=(10,5),grid=True);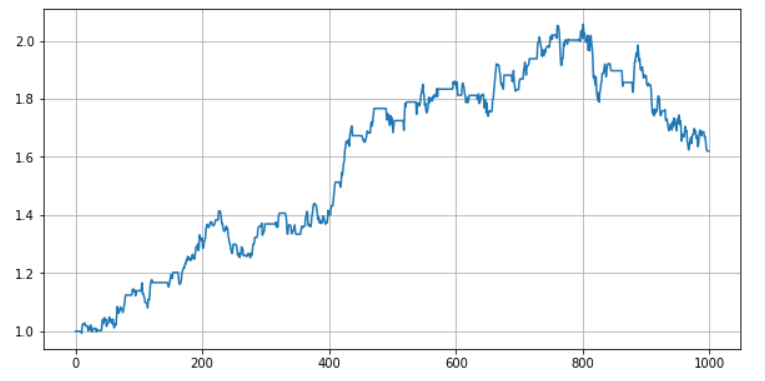
可以看到,搬砖模型虽然也有超额收益,但由于叠加了多头走势,在标的趋势向下的情况下,搬砖模型也会遭遇很大的回撤。那么,有没有办法减小回撤呢?我们马上想到了资产组合理论,同时交易很多低相关的资产可以降低回撤。
三、组合搬砖模型
接下来,我们假设可以找到100组这样的序列对,对每组序列上面进行搬砖交易, 然后把收益曲线组合在一起。
pricedf_a=(pd.DataFrame(np.random.normal(0,0.01,(1000,100)))+1).cumprod()
pricedf_b=pricedf_a.apply(lambda x:x+generate_reverse_serise(1000))
forward_return_a=pricedf_a.pct_change().shift(-1)
forward_return_b=pricedf_b.pct_change().shift(-1)
signal=(pricedf_a-pricedf_b).apply(signal_func)
signal_a=signal[signal>0].fillna(0)
signal_b=-signal[signal<0].fillna(0)
pnl_a=(signal_a*forward_return_a).sum(axis=1)/signal_a.sum(axis=1)
pnl_b=(signal_b*forward_return_b).sum(axis=1)/signal_b.sum(axis=1)
pnl=(pnl_a+pnl_b)/2
(pnl+1).cumprod().plot(figsize=(10,5),grid=True);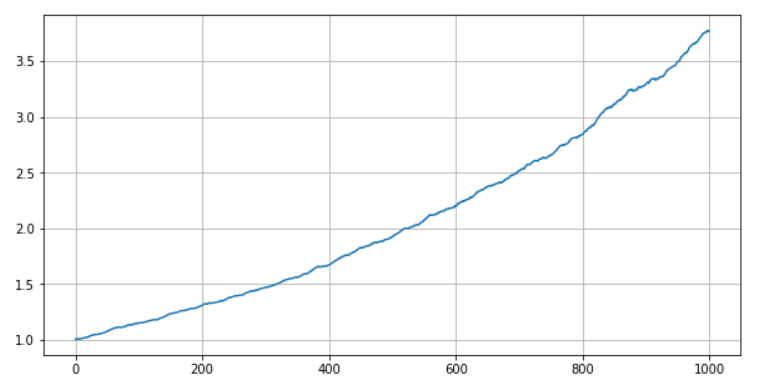
我们惊奇地发现,组合起来的收益呈非常完美的指数向上走势。其实大可不必惊讶,因为我们随机生成的这100个组合之间是完全无关的,即相关性为0,按投资组合理论确实可以得到这样完美的结果。
接下来我们想一想还有没有优化空间?我们在生成a、b两组序列时,a序列是随机游走的,而b序列则是在a的基础上叠加了一个均值回归的走势。从逻辑上分析,对于随机游走的序列是不存在可获利策略的,那么所有的收益来源只可能在b序列上。为证实我们的猜想,我们把上一步计算中得到的pnl_a和pnl_b分开来看一下。
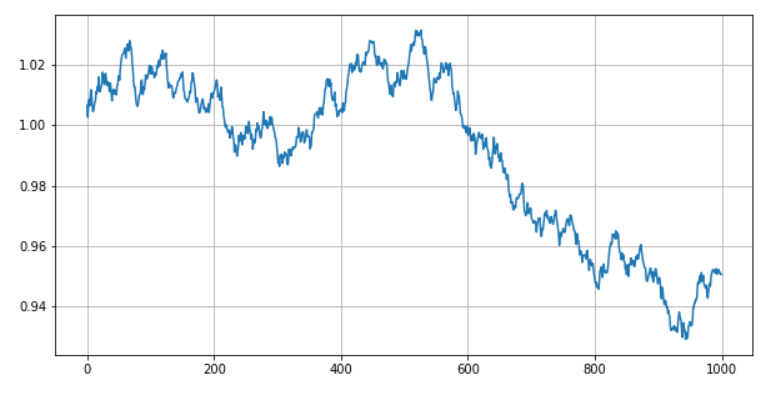
下图是pnl_a的累计曲线。
下图是pnl_b的累计曲线。
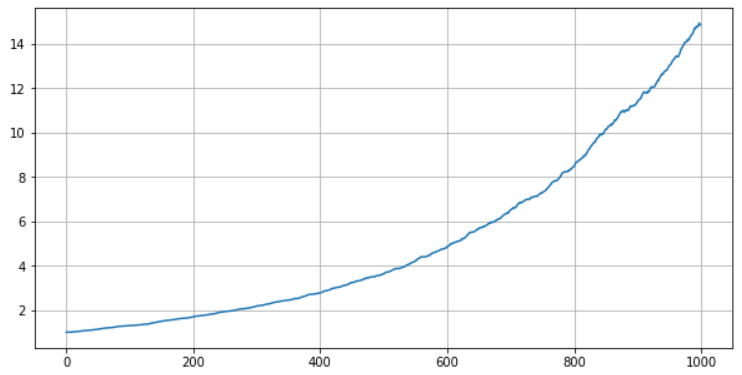
我们的猜想是正确的,在搬砖模型组合中,a序列组不贡献收益,而b序列组则持续贡献超额收益,也就是说,我们只需要对b序列组进行操作,而a序列组由于是随机游走的,其综合收益最终会因足够分散而接近于0。
我们再来向现实靠近一步。在现实中,我我们一般只能从逻辑上推测价差一定回归,但很难提前预知价差的波动范围,从而难以实现如上所示的搬砖套利。但如果我们能合理假定很多个价差组合一定程度上具有同质性,我们就可以用价差的相对大小来衡量价差回归的胜率和赔率,从而可以不需要确定的价差阈值,而只是根据价差来选择相对最优的标的。终于,我们来到了本文的主角,轮动模型。
四、轮动模型
我们对上面的搬砖组合做个变形,只做b序列的部分。在b序列的信号生成时,不再是设置b-a在某个阈值区间做多,而是比较各个b-a价差在横截面上的相对大小,选择价差最小的几组b序列单向做多,即可获取统计套利的收益。当组合数量足够多时,a序列的波动风险将可以被分散到最小。
这部分的回测大家比较熟悉了,我们直接给出回测结果。
pnl=calc_pnl(filtTopN(pricedf_b-pricedf_a,20),forward_return_b)
(pnl+1).cumprod().plot(figsize=(10,5),grid=True);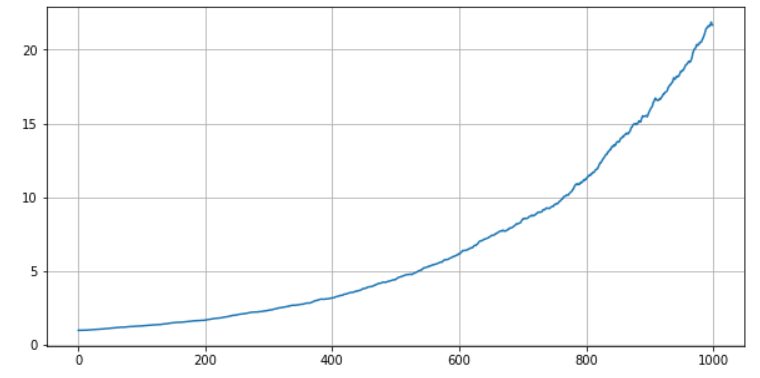
进一步向现实靠拢,a序列之间的相关性不可能是0,反而是高度相关的,在这种情况下,a序列的波动风险将不能被完全分散,最终我们不得不承受市场的平均风险。
五、总结
最后再回顾一下,我们构建的轮动模型有两个前提:
1、a序列组可视做随机游走;
2、b序列组与a序列组高度相关,且b序列组有向a序列组收敛的趋势。
最后得到了如下结果:
1、通过轮动b序列,可以在不对价差进行精确预测的前提下获取统计套利收益。
2、通过资产组合,可在单向做多的限制条件下,有效分散单个序列自身的波动风险。
3、由于市场风险不可分散,这将是我们不得不承受的风险。
由此,我们可以进一步推论,轮动模型获利的条件:
1、价差回归的逻辑成立。
2、价差有可观的波动空间。
ST牧羊
 - 此人不学无术,贪财好色,与人常做无谓口舌之争,遇事夸夸其谈百无一用,判其投胎南瞻部洲,当一股民,昼则殚精竭虑交易,夜则膏油继晷复盘,终年盘桓于三千点,账户缩水日甚一日,活活亏煞他罢了
- 此人不学无术,贪财好色,与人常做无谓口舌之争,遇事夸夸其谈百无一用,判其投胎南瞻部洲,当一股民,昼则殚精竭虑交易,夜则膏油继晷复盘,终年盘桓于三千点,账户缩水日甚一日,活活亏煞他罢了
赞同来自: gaokui16816888
所有的券商自营盘都是这么考核的。又有绝对又有相对,所以券商自营部门的部门负责人,行业平均是2-3年换一轮。只有神才能满足大股东的要求。
我认识的好几个券商自营的负责人,几年一看基本上都换光了,这就业环境比公募基金只讲相对收益要差多了。
所以很多自营的人也是保险或公募出来,谈好机制,看好时机,出来捞一把分成,然后自己出去干私募了的。
即使有高手,也对付不了猪队友!
赞同来自: 青火
我的理解一般聊sharpe都是日频的,当然如果策略跑的时间很短的话,算出来的sharpe不可靠。其实说到底还是跟采样的数据点数量有关时间太短是一方面,但同样可能夸大也可能缩小,资产管理机构的问题主要是回填,选择性报告,幸存者偏差和盈余管理,导致系统性夸大回报和掩盖风险。当然什么行业都是搞鬼的,最多资产管理行业水平比平均更高一些而已。
ST牧羊
- 此人不学无术,贪财好色,与人常做无谓口舌之争,遇事夸夸其谈百无一用,判其投胎南瞻部洲,当一股民,昼则殚精竭虑交易,夜则膏油继晷复盘,终年盘桓于三千点,账户缩水日甚一日,活活亏煞他罢了
期待阁下的产品,如果存在的话。笑了,夏普2的就是典型的波动率平滑的或/和高尾部风险实际高度负阿尔法靠运气的产物了,还真想继续骗不懂的人啊,svxy这种光看16-17也能有夏普2呢,arkk光看19-20类似,长期来看相对spy是高度负阿尔法。可惜他们不能学对冲基金平滑波动率和选择性报告业绩,搞幸存偏差,孵化偏差和选择报告偏差(公墓也有,没那么严重,因此比私募还没那么差),否则怎么也能吹成夏普上4或者5。如果能学私人资产行业那样按季度报告业绩的话,夏普上10,100或1000都不成问题,和p2p一样稳(笑)
夏普到2再聊。
不,我的意思是你想割韭菜就去吧,我搞量化的。原来搞量化的不是割韭菜的啊,那你的对手盘是谁?
看你这个自信劲,原来还是真傻,不是装的。类似于我认识的老师,把洗脑学生听话的东西自己也当真,生活里也怂的很,就敢在学生和子女面前凶
我以前以为行业内真傻的人是10%,现在看来是90%以上乃至99%以上,无怪乎各种资管都提供越复杂越不透明越大的扣费前负阿尔法。除了有意坑人外,自己真傻也很重要。不是真傻,就算拼命坑客户,好歹扣费前相对最无脑基准的阿尔法不明显为负,比如至少不会搞统计“套利”之类的实为做空波动率的玩意而相对指数基金有显著的负阿尔法
做统计“套利”的人当然存在,只是效果不会超过而基本上不如最简单的短期反转因子而已,上次是用因子给统计“套利”贴金,这里就直接竖稻草人加人身攻击了我用对冲基金的文章回的是你说对冲基金有超额,说统计“套利“无效靠的是论文里统计套利效果弱于或不强于短期反转因子,以及你甚至故意混淆对冲基金的相对价值/套利策略大类和统计“套利“之间的关系,把因子投资有效说成统计“套利“有效。这不过是红鲱鱼谬误,转移话题而...期待阁下的产品,如果存在的话。
夏普到2再聊。
拿着什么评价对冲基金行业的文章,想证明美股多空统计套利不存在,可见你是一丁点没做过。有啥讨论必要么。做统计“套利”的人当然存在,只是效果不会超过而基本上不如最简单的短期反转因子而已,上次是用因子给统计“套利”贴金,这里就直接竖稻草人加人身攻击了
不回了,污染环境。
我用对冲基金的文章回的是你说对冲基金有超额,说统计“套利“无效靠的是论文里统计套利效果弱于或不强于短期反转因子,以及你甚至故意混淆对冲基金的相对价值/套利策略大类和统计“套利“之间的关系,把因子投资有效说成统计“套利“有效。这不过是红鲱鱼谬误,转移话题而已,污染环境的自我介绍挺准确
“你写那一长串处处不通,没有讨论价值。是真的,处处不通。”这种被揭穿明显的错误 - 混淆因子投资和统计套利,似乎都有多空就都一样,然后干脆说统计“套利“不存在的所谓“(属于一个)策略大类”,- 后的嘴硬也是挺准确的自我评价,可惜缺乏自知之明,不知道自己是在投射
让我想起有些论文里提到统计套利是把做空波动率也叫统计“套利”,虽然实际上做空波动率策略是有负阿尔法的,您这种表现就更加说明为什么对冲基金有扣费前负阿尔法了,我现在就等哪个做私人资产的像恁这样告诉我他们如何击鼓传花的真相
资管行业(和很多其他行业一样,只是程度可能比很多行业更强)的确就是这么个样子,你也不得不承认这“说的挺清楚的” “定位挺合适“,那可以认为你赞同我说的了吧(笑)拿着什么评价对冲基金行业的文章,想证明美股多空统计套利不存在,可见你是一丁点没做过。有啥讨论必要么。
不回了,污染环境。
资管行业(和很多其他行业一样,只是程度可能比很多行业更强)的确就是这么个样子,你也不得不承认这“说的挺清楚的” “定位挺合适“,那可以认为你赞同我说的了吧(笑)不,我的意思是你想割韭菜就去吧,我搞量化的。
你写那一长串处处不通,没有讨论价值。是真的,处处不通。
有的事儿你觉得做不到,那就以你为准。
哈哈哈以为咱俩算同行,多说几句。现在看来不是同行。一开始你就说我是外行,还是抓住这个说事,我也说了还没入行,现在又说自己以为我是同行了(笑)
相对价值和套利这两个大类你都混起来讲,还要硬扯上统计“套利”<恁这说的倒是还是真有点太外行,和面向低认知读者的割韭菜marketing内容挺像,例如把统计“套利”吹成是套利类策略,然后和相对价值类策略混起来讲
看你表现看来不像是真信之前那套说辞,看到我指出问题就挂免战牌了。那还好,看来行业内的人还不至于都蠢到相信自己骗客户的那套东西
你把自己想入的行是个什么样子,说的挺清楚的。定位挺合适。资管行业(和很多其他行业一样,只是程度可能比很多行业更强)的确就是这么个样子,你也不得不承认这“说的挺清楚的” “定位挺合适“,那可以认为你赞同我说的了吧(笑)
@Campanella第一,对冲基金整体不提供超额收益,不等于所有对冲基金都不提供超额收益。第二,美股单因子多空提供无成本负beta的etf产品都出来好多年了,就是美股多空统计套利策略有效性的明证,结论一目了然。第三,非从业人员,想证明市场上一个成熟的大类策略是扯淡,与民科无异。甚至资深从业人员都不该评价自己没做过的资产类别与量化策略。第四,抱着割韭菜而不是创造价值的想法,那最好别进资管行业。对...哈哈哈以为咱俩算同行,多说几句。现在看来不是同行。
@Campanella第一,对冲基金整体不提供超额收益,不等于所有对冲基金都不提供超额收益。第二,美股单因子多空提供无成本负beta的etf产品都出来好多年了,就是美股多空统计套利策略有效性的明证,结论一目了然。第三,非从业人员,想证明市场上一个成熟的大类策略是扯淡,与民科无异。甚至资深从业人员都不该评价自己没做过的资产类别与量化策略。第四,抱着割韭菜而不是创造价值的想法,那最好别进资管行业。对...你把自己想入的行是个什么样子,说的挺清楚的。定位挺合适。
赞同来自: 南瓜猫
第一,对冲基金整体不提供超额收益,不等于所有对冲基金都不提供超额收益。
第二,美股单因子多空提供无成本负beta的etf产品都出来好多年了,就是美股多空统计套利策略有效性的明证,结论一目了然。
第三,非从业人员,想证明市场上一个成熟的大类策略是扯淡,与民科无异。甚至资深从业人员都不该评价自己没做过的资产类别与量化策略。
第四,抱着割韭菜而不是创造价值的想法,那最好别进资管行业。
- 对冲基金整体哪里是不提供超额的问题,是gross of fee提供负超额的问题,就是负的多少的问题,不等于所有对冲基金都不提供不稳定的伪正超额真负超额收益
- 拿因子策略给统计套利贴金,不要太搞笑,不是都做多空都一样的。你这样用非常明显的假话嘴硬,就是美股美股统计套利策略无效性的明证,结论一目了然。
- “自称从业人员,想证明市场上一个成熟的大类策略因子投资是统计套利,与民科无异”而且什么时候统计套利是一个策略大类了?宏观、CTA、相对价值、多空这些才是策略大类——虽然实际上宏观和CTA几乎是期货趋势跟踪一类,多空和相对价值也几乎是股票因子敞口加市场贝塔,但就算分这么细,哪来的统计“套利”策略大类?就算是分到做多波动性/做空波动性/尾部风险这种期权策略的小类也没统计套利这种策略分类
- 所谓“资深从业人员都不该评价自己没做过的资产类别与量化策略”就是典型的割韭菜说法,例如主动基金不行,那主要不是从业人员自己曝光的,是Fama之类的学者用证据打脸揭穿的,Asness现在也来打脸私人资产行业。
- 恁这种“只有我们圈内人才能评价,其他人不仅不能评价,而且评价就是坏,就是错”,是典型的腐败圈子的防御性反应,好像别人看你声称明显荒谬的“只要是多空都一样,因子有效就说明统计套利有效”还不能看出你问题似的——反过来倒是可以,所谓“统计”套利“有效”只是说明短期反转因子有效
- 当然这种还要标榜“你才割韭菜,我们很高贵,我很有品德”的“抱着割韭菜而不是创造价值的想法,那最好别进资管行业”,我自然也很欢迎你这样蒙骗大家,方便我以后从业,就是怕你是真信了,那我对这个行业的从业者的水平和品德就更看低一层了,当然也更有信心了
- 就算是真能帮客户做出超额,什么时候那不是靠割别的韭菜而不是只割客户一个韭菜而居然算是所谓“创造价值”了?林园说的“咱们都是寄生虫”还比较诚恳,当然这可能也只是更高一级的骗术
- 我也更加明白为什么对冲基金能骗到不少人了(包括jsl某些“大佬”),就是恁这种marketing的无耻(或者还要加上无知?)劲儿够足,够会摆姿态装模样,用认知筛选的话术(例如声称因子投资“证明”统计套利能行)骗目标客户,和我原本了解到的情况相差无几。感谢恁教我以后怎么干这行
赞同来自: 火锅008 、wangchengf
Asness做对冲基金的,你是说他的研究是“主观臆测自己没做过的事情不可取”对吧?他的结论就是,对冲基金是用高昂的费用提供市场贝塔,完当然私募股权会更糟糕,他最近经常批私募股权出于我自己的利益,我其实更希望大家愿意为市场贝塔付高额费用……这也是金融界一直以来的发展方向第一,对冲基金整体不提供超额收益,不等于所有对冲基金都不提供超额收益。
第二,美股单因子多空提供无成本负beta的etf产品都出来好多年了,就是美股多空统计套利策略有效性的明证,结论一目了然。
第三,非从业人员,想证明市场上一个成熟的大类策略是扯淡,与民科无异。甚至资深从业人员都不该评价自己没做过的资产类别与量化策略。
第四,抱着割韭菜而不是创造价值的想法,那最好别进资管行业。
主观臆测自己没做过的事情不可取呢。Asness做对冲基金的,你是说他的研究是“主观臆测自己没做过的事情不可取”对吧?
他的结论就是,对冲基金是用高昂的费用提供市场贝塔,完
当然私募股权会更糟糕,他最近经常批私募股权
出于我自己的利益,我其实更希望大家愿意为市场贝塔付高额费用……这也是金融界一直以来的发展方向
赞同来自: wangchengf
我知道私墓扣费前都跑不赢公墓,但是不那么清楚原因,就看过一大堆私墓业绩数据和研究(比如Do Hedge Funds Hedge?)后知道反正是骗钱的,我现在就更清楚原因了……当然我非常支持jsl的大家去买私募,毕竟我也准备以后干这行,还是不能砸自己(未来的)饭碗,就像我非常支持基民加仓基金帮我抬轿,非常鼓励股民相信因子失效,非常赞同买可转债的只知道低策略觉得隐波差没用信用评级没用一样主观臆测自己没做过的事情不可取呢。
我不知道您对美股统计套利的成见是哪儿来的,但我敢说它有效是因为我在对冲基金的时候就是做这个的。我知道私墓扣费前都跑不赢公墓,但是不那么清楚原因,就看过一大堆私墓业绩数据和研究(比如Do Hedge Funds Hedge?)后知道反正是骗钱的,我现在就更清楚原因了……当然我非常支持jsl的大家去买私募,毕竟我也准备以后干这行,还是不能砸自己(未来的)饭碗,就像我非常支持基民加仓基金帮我抬轿,非常鼓励股民相信因子失效,非常赞同买可转债的只知道低策略觉得隐波差没用信用评级没用一样
由于统计“套利”实际上是暴露于短期反转因子,就算几千只也会遇到系统性风险而且很多统计上显著的“套利”实际上没有考虑或严重低估交易成本,侥幸成功也不过是高度暴露于因子然后因子表现较好例如近年做交通运输行业的统计“套利”的话就会表现很好,但其实不过是暴露于短期反转因子,而短期反转因子近年在交通运输行业表现较好如果不考虑交易成本和做空限制,那A股07年到今天短期反转因子百分位多空组合年化收益率能达到1...我不知道您对美股统计套利的成见是哪儿来的,但我敢说它有效是因为我在对冲基金的时候就是做这个的。
谢谢回复按你的设置,即使用过时的申万2014行业分类,我测出来选十只的总收益也是6.23%,选申万2021行业分类跑出来甚至是15.99%,比我原本说的还好,当然,收益波动性要比沪深300大很多,但的确有的赚
果仁交易成本是按照单边千2算的,20倍换手,8%的成本,降低换手,能多赚4%,有用却并不显著。
打开果仁新建策略,选择二级行业半导体,选择包含科创板,排名条件加入20日涨幅从小到大排列,交易模型选择模型II,回测,收益2.94%,挺寒酸的。选择排除科创板,到6.6%了。新股理想仓位设置到20%,到10.86了……这个路径还可以继续,但是我觉得已经陷入拟合过程了。通常我认为模型回测是用来证...
至于谈显著不显著,就完全不能只拿一年的数据来测了,一年的数据再好也谈不上显著,还谈到过拟合和换手率
所以大家也明白为什么美股瞧不起统计套利了吧?因为统计套利依赖于的短期反转因子受制于交易成本,只能用来排除错误的进出时间点,却不适合单独用来赚钱。单独用这个来“赚钱”,还各种调参过拟合,还美名曰套利,这种赔钱手艺简直不要被太瞧不起
倒是选择二级行业高速公路,可以到43%。只是,如果排名条件反转,居然也有12%收益率;或者时间拉长到2019年,是51%按你的设置,19年5月到昨天高速公路用排名条件反转的20日涨幅因子年化是-17.71%,哪来的51%?是总回报-51%还差不多。从小到大倒是有9%
所以你可以不用预测,就用简单的短期反转谢谢回复
你是用了果仁的模型I,这样会导致换手率太高而且大多数涨幅吃不到
换成模型II,前10才买,出前20才卖,换手率从2000%降到1200%,一年跑下来收益10.18%
去掉大盘好是因为市值因子最近强力,不是因为大盘股不讲反转,300亿以上大盘半导体股里反转IC还是有0.077
你原本提到的交通运输行业近一年用这一策略收益32.68%,远远跑赢行业指数5% ,I...
果仁交易成本是按照单边千2算的,20倍换手,8%的成本,降低换手,能多赚4%,有用却并不显著。
打开果仁新建策略,选择二级行业半导体,选择包含科创板,排名条件加入20日涨幅从小到大排列,交易模型选择模型II,回测,收益2.94%,挺寒酸的。选择排除科创板,到6.6%了。新股理想仓位设置到20%,到10.86了……这个路径还可以继续,但是我觉得已经陷入拟合过程了。通常我认为模型回测是用来证伪的,当我觉得反转合乎逻辑的时候,用最简单的回测能出来一个不错的IC,并不一定能证实,但是如果IC不行,就足够证伪了。把排序条件反转,通常应观测到负IC,则说明因子有效。严格说还要做分层测试。只是大多数因子到这一步就看不下去了。
至于提到的交通运输一级行业,我并未测试到这个收益率,倒是选择二级行业高速公路,可以到43%。只是,如果排名条件反转,居然也有12%收益率;或者时间拉长到2019年,是51%。简单来说我并不觉得是一个显著有效的因子。我觉得应该没有人会直接用这种策略跑吧
赞同来自: 只因集 、skyblue777
事实上美股统计套利仍然并且将长期有效,市场始终是不有效的,只是发现不有效的数据门槛很高。美股统计套利无效并不是因为市场有效,实际上美股排除样本内过拟合外因子效力下降并不多,而是因为统计套利的效果在排除(当时的)交易成本后一直很差,过于复杂的方法很容易过拟合,类似做空波动率会一下子把之前赚的和本金一起赔进去,就和基金抱团一样是伪超额真输光内裤,所以会被人瞧不起
举一个最简单的例子,美股高beta股票的长期收益并不比低beta股票高,那么统计上做空高beta股票就比做空低beta划算,因为可以获得额外的负beta,即使考虑做空成本也是这样。
所以即使是美股,即使是beta这么简单的因子,也是长期无效的。这就是统计套利始终可以存在下去的原因。
另外,您说的对于统计套利的...
不是越复杂的东西鄙视链越高,看复杂度算鄙视链算是外行了,内行讲的都是简胜于繁:
本文开发了一个使用 22 年交易期、多达 300 个美国大盘股和大约 600 个预测变量的应用程序。实证结果强调了这些技术能够为具有高周转率和短期持有期(一或五天)的投资组合生成有用的交易信号。在考虑交易成本和传统风险因素后,超额回报大幅减少。当这些机器学习工具在市场上随手可得时,超额回报最近变成了负数。结果还表明,添加功能远不能保证提高投资组合的 alpha。学习统计套利的机器学习算法学到最后,主要学到的还是波动率因子和反转因子,甚至不如加强后的短期反转因子有效
这是因为金融数据的小数据集,低信噪比和高度相关的特征导致金融模型不适合太复杂,否则很容易过拟合。高频倒是可以用更大的数据集来进行训练,但统计套利要等价差缩小又不能学高频那样快进快出
至于综合其他股票的信息提供因子,如分离短期动量因子以改进短期反转因子,这倒是正路,统计套利则不是,所以被人瞧不起。统计套利也不如高频策略相对没那么不稳定不可靠,所以就像中盘股那样两头受气
回另一位的
统计套利又不是非得限定在两个之间,像worldquant这种,都是long几百只,short几百只。就算有那么几只劈叉,也不影响什么由于统计“套利”实际上是暴露于短期反转因子,就算几千只也会遇到系统性风险
而且很多统计上显著的“套利”实际上没有考虑或严重低估交易成本,侥幸成功也不过是高度暴露于因子然后因子表现较好
例如近年做交通运输行业的统计“套利”的话就会表现很好,但其实不过是暴露于短期反转因子,而短期反转因子近年在交通运输行业表现较好
如果不考虑交易成本和做空限制,那A股07年到今天短期反转因子百分位多空组合年化收益率能达到180%,完爆同类设置下在美股靠一大堆机器学习算法里精选才最多90%,但实际上因为A股做空难以及交易成本问题,跑出来只能是负收益
赞同来自: skyblue777
机器预测动量还是反转?这个东西没有逻辑支撑,妥妥的过拟合,实战不敢用吧。所以你可以不用预测,就用简单的短期反转
你这个简单反转因子,很容易测。大家用动量是觉得偏机构行为,用反转是觉得偏散户行为,所以反转因子,逻辑上在偏小市值上更明显。果仁上简单测一下,选二级子行业半导体,根据20天涨跌幅排名,选最低的10只,跑下来一年亏了9%,跑输了半导体指数,波动还很大。但是如果把市值限制到300e以下,跑出正收益来了。相关的测试跑了几个组合,感觉...
你是用了果仁的模型I,这样会导致换手率太高而且大多数涨幅吃不到
换成模型II,前10才买,出前20才卖,换手率从2000%降到1200%,一年跑下来收益10.18%
去掉大盘好是因为市值因子最近强力,不是因为大盘股不讲反转,300亿以上大盘半导体股里反转IC还是有0.077
你原本提到的交通运输行业近一年用这一策略收益32.68%,远远跑赢行业指数5% ,IC0.13
实践中用正交 非线性可以改善性能
把回测时间限定在17年抱团股行情开始到现在,市值300亿以上的股票反转因子IC仍然有0.013,中国没有所谓大盘股讲动量,美股才有这一特征,仅限于最近一年的结果类似
动量还是反转是可以用机器学习算法预测的,用一大堆股票算b指的是用最相关/协整的几十只股票求平均合成一个b序列,在此基础上搞些协整过0点次数之类的方法理论上可以提高性能,但太容易过拟合了就算了机器预测动量还是反转?这个东西没有逻辑支撑,妥妥的过拟合,实战不敢用吧。
真要搞还是用简单的办法,就是用行业内反转效应,行业内短期表现差的股票未来一个月表现好,例如601872过去一个月跌幅大,未来更可能在航运板块中相对表现好,这就是我说的配对交易利润来源基本上是短期反转因子
除了...
你这个简单反转因子,很容易测。大家用动量是觉得偏机构行为,用反转是觉得偏散户行为,所以反转因子,逻辑上在偏小市值上更明显。果仁上简单测一下,选二级子行业半导体,根据20天涨跌幅排名,选最低的10只,跑下来一年亏了9%,跑输了半导体指数,波动还很大。但是如果把市值限制到300e以下,跑出正收益来了。相关的测试跑了几个组合,感觉就是,在二级行业内用反转因子,需要做空大市值跌的多的,做多小市值跌的多的,组合起来跑还能有个还凑合的收益。我之所以不喜欢,是因为波动太大
至于“用一大堆股票算b指的是用最相关/协整的几十只股票求平均合成一个b序列”,是不是类似用50只股票拟合hs300,然后用偏差来判断持有哪个?过零的频率越高,实际上对应超额收益越多?这算是个指数增强策略吧,倒是没研究过
dhhlys - 积重而返
赞同来自: 泛舟Rain
这个能否展开说说?动量还是反转是可以用机器学习算法预测的,用一大堆股票算b指的是用最相关/协整的几十只股票求平均合成一个b序列,在此基础上搞些协整过0点次数之类的方法理论上可以提高性能,但太容易过拟合了就算了
我是否能理解为,000520和600798有相关性,但是600798有一部分陆运,所以应该是600798等于000520和一个陆运标的的组合,进行配比;如果配比完成,发现残差的异常,然后去分析是否是基本面因素的显著变化,如果是基本面的变化,就按动量来处理,否则按反转?
这么搞是不是太麻烦了
真要搞还是用简单的办法,就是用行业内反转效应,行业内短期表现差的股票未来一个月表现好,例如601872过去一个月跌幅大,未来更可能在航运板块中相对表现好,这就是我说的配对交易利润来源基本上是短期反转因子
除了去掉市场贝塔和行业贝塔外,去掉其他因素贝塔(如市值)会进一步增强这种短期反转的效力
如果计算上考虑进非线性因素,可以进一步提高效力,但这和机器学习预测反转还是动量那样,太麻烦了
赞同来自: 好奇心135 、ST牧羊 、青火 、ylxwyj
就算是美股的散户交易者至少也知道要玩a-bx-y,楼主说的单纯a-b也就是brka和brkb这种完全对应的标的能用,你说的指数和指数期货之间也可以,转债和正股都不能这么简单搞,因为转债隐含期权的delta基本上不是1好的方法要么用非线性相关要么用多个对应的标的来算b(假设操作的对象是a),后者基本上等于短期反转,而且经常要区分残差变化是动量还是反转,两者都能赚钱,但分不清就会亏钱这些根本来说并不...事实上美股统计套利仍然并且将长期有效,市场始终是不有效的,只是发现不有效的数据门槛很高。
举一个最简单的例子,美股高beta股票的长期收益并不比低beta股票高,那么统计上做空高beta股票就比做空低beta划算,因为可以获得额外的负beta,即使考虑做空成本也是这样。
所以即使是美股,即使是beta这么简单的因子,也是长期无效的。这就是统计套利始终可以存在下去的原因。
另外,您说的对于统计套利的鄙视链大概率不存在,美股统计套利的数据复杂程度超过hft和各类衍生品。
赞同来自: gaokui16816888 、流沙少帅 、甘泉 、nkfish 、大魏忠臣毌丘俭 、更多 »
补充一下我这里关于此类策略中实证情况下的观察:就算是美股的散户交易者至少也知道要玩a-bx-y,楼主说的单纯a-b也就是brka和brkb这种完全对应的标的能用,你说的指数和指数期货之间也可以,转债和正股都不能这么简单搞,因为转债隐含期权的delta基本上不是1
这里的策略假设a-b序列本身是随机游走的,但在实务中,我们经常会观察到一个特征,即a-b序列与a序列会呈现出特定的相关性,尤其以负相关为主。
这种现象往往出现在a与b的流动性、投资者结构、投资者风险偏好不同的情况下。
而当a-b序列与a序列呈现出负相关特征的时候,我们会发现做多b序列的超额收益被a序列本身的下行风险所抵消,即我们会发现:每次做多B赚钱...
好的方法要么用非线性相关要么用多个对应的标的来算b(假设操作的对象是a),后者基本上等于短期反转,而且经常要区分残差变化是动量还是反转,两者都能赚钱,但分不清就会亏钱
这些根本来说并不是套利,而是用其他标的的价格信息预测个股短中期相对表现,归结来说还是动量和反转,和用基本面预测货币乃至加密货币走势没什么区别,实际上赚的还是因子风险溢价
在美股专业量化领域,统计“套利”是被人看不起的“就算现在赚钱,以后肯定会破产”,而且AQR的多样化套利基金玩封基玩可转债玩SPAC就是不玩统计套利,可能中国现在还比较嫩,玩这套还能赚钱
赞同来自: AZ90 、传达室李老伯 、flybirdlee 、dingo49 、wanghc02 、 、 、 、 、 、更多 »
这里的策略假设a-b序列本身是随机游走的,但在实务中,我们经常会观察到一个特征,即a-b序列与a序列会呈现出特定的相关性,尤其以负相关为主。
这种现象往往出现在a与b的流动性、投资者结构、投资者风险偏好不同的情况下。
而当a-b序列与a序列呈现出负相关特征的时候,我们会发现做多b序列的超额收益被a序列本身的下行风险所抵消,即我们会发现:每次做多B赚钱的时候,A序列的状态往往不是随机游走状态,而是A序列多头表现较差的时刻。
因此,最终的策略表现会被侵蚀。
这种现象在2022年以后特别明显,体现了一定的普遍性,在诸如:正股价格变化导致的转债溢价率变化、强赎概率波动导致的转股溢价率变化或IC、IM相对指数的定价等等方面,都有较为明显的体现。
这可能是市场有效性提升的特征表现,即套利者本身开始影响市场定价的特征,供参考。

海浪头头 - 善输小错者赢
赞同来自: 自由之梦想 、白湖水 、dadavid 、Jifandailu
轮动标的:150171和150200,轮动方式:满仓轮动
如果从0.75元一路涨到0.90元
总收益=持有收益(0.90-0.75)+轮动收益
如果从0.90元一路跌到0.75元
总收益=持有收益(0.75-0.90)+轮动收益,
结论很明显:在0.75元开始轮动到0.90元,总收益才能实现收益最大化。
而从0.90元一路轮动到0.75元,这时要看轮动收益能不能大于持有亏损。
这结论其实很简单,去年很多人赚到可转债的钱
可转债=100起步+轮动收益
但其实可转债,实际上赚的是中证500上涨的钱
楼主提出的观点:1、资产组合尽可能不相关2、均值回归
但现实中我感觉很难实现,就是楼主大家说的,样本太少了。
封基折价轮动、A类轮动、可转债轮动,有的已经清盘了,有的还高估。
再看楼主2021年总结的贴子,我明白了一个道理。
只有扩大能力圈,然后找到多种具备均值回归的品种,而且要低相关的,然后构建成一个组合,这样才能大概率实现均值回归。
这一点鸭蛋有说过,分散持有100个转债,这样均值回归胜率高,但持有期权只有1个,这样大数定律就实现不了了。
再次感谢楼主的贴子
赞同来自: Johnnyx1987
任何标的都有崩溃消亡的风险,比如股票的退市
总体上,套利者更多要考虑仓储的安全性风险,这一点,就算转债等标的其实也是一样的
赞同来自: 丘丘人炖史莱姆 、灵活的蓝胖子 、mercykiller 、wangchengf 、foxbat981 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、更多 »
相比无风险套利,统计套利更坑。无风险套利大不了是没机会,统计套利会出现假机会,明明套利关系打破了,价差呈趋势波动不回归,但你不知道,看上去象大机会。往往是千日砍柴一日烧光。
具体到轮动上面,就是牛票统统卖飞,最后轮到坑里。
胆子真不大
- 股债平衡
赞同来自: 邹大仙女 、宋一堆 、xixili2020 、zsp950 、wuchunlong更多 »
欧阳修 - 没有长生稻,也没有荒芜田!
赞同来自: 丶丶丶丶 、fjqzjf 、tangzheci 、小小野鹤 、清舜 、 、 、更多 »
转股价值取决于正股价格与转股价,转股价不变,也就取决于正股价格,取决于正股。
转债价格与转股价值的比值减1就是溢价率。随着转股期到来,转债价格会向转股价值回归,也就是溢价率趋于0。
楼主的回测论证了单靠轮动溢价率可以获得收益,获得的收益与正股无关。
这个适合于存在折价的品种,可转债相对于正股、折价基金相对于基金净值、期货跌水相对于现货。
这个也解释了为什么可转债低溢价策略要强于双低策略,低溢价看似高风险而其风险实际并不比双低策略高。
赞同来自: 尹申 、songsong0808 、mercykiller 、皮叔 、骑蜗牛士 、 、 、 、 、 、 、 、更多 »
赞同来自: ValueArtist 、newsu 、包包123 、你猜再猜 、湘漓浪云 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、更多 »
但现实中往往更常见的是,配对组差价的拉开,其实是源于标的贝塔存在潜在负预期。也就是阿尔法和贝塔动力往往是相反的,标的价格并非随机运动。
拿可转债低溢价轮动来举例就是,低溢价往往源于超涨,而超涨回调是统计学上确实存在的负贝塔。
所以有效性其实取决于市场认知差,这个并非一直有效,做轮动的资金多了阿尔法就会削弱。
类似的情况还有当初的分级B折价轮动。
赞同来自: yangkaizeng
1. 溢价率接近0时,可转债波动率比正股高,是非常合适的轮动交易对象。
2. 当可转债越多、对应正股相关性越低时,策略越有效。
 京公网安备 11010802031449号
京公网安备 11010802031449号