 Edge
Edge Chrome
Chrome Firefox
Firefox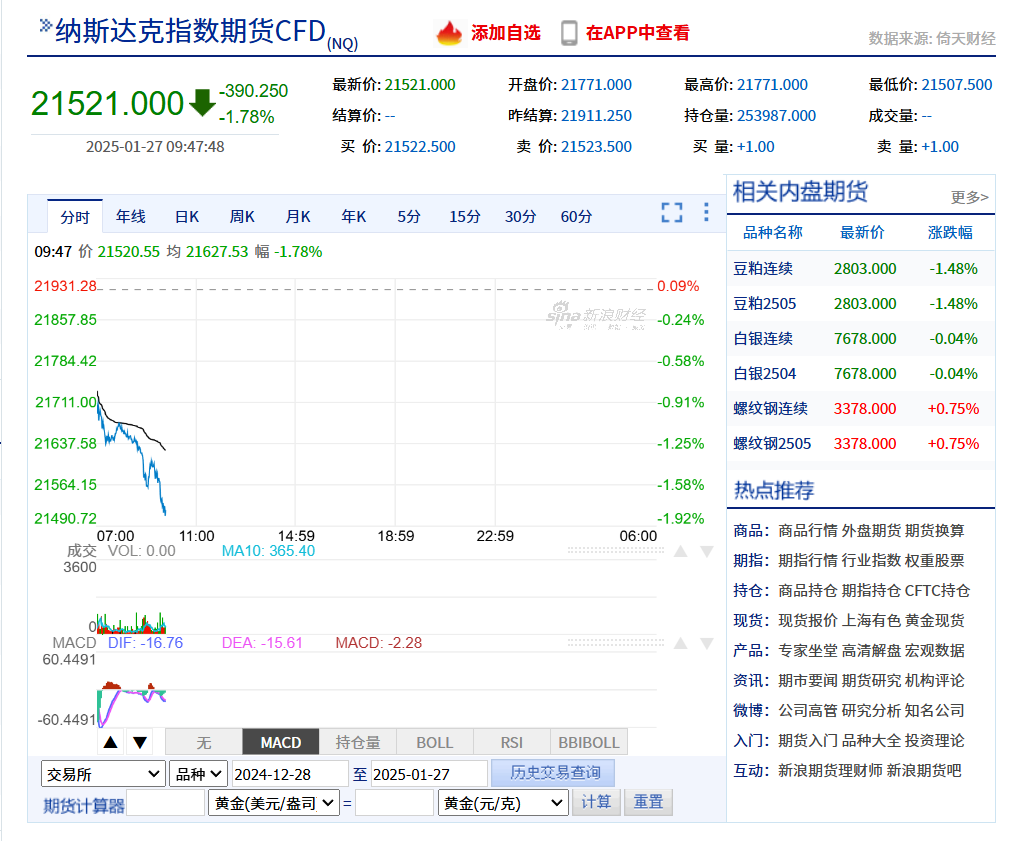
赞同来自: 雷神2019
信你一次 79.8买了点tqqq 希望收盘能涨回去我没回测纳指,纳指那部分我是吐槽用的,a50部分是回测的。
没涨回去算我自己sb
a50这个是统计一般趋势,考虑到费用和滑点后,不适合交易。
赚了是您远见卓识~
zoetina52
 - 以前什么都不懂,日子过得好好的。后来我学习了些理财知识,家里的钱越理越少。
- 以前什么都不懂,日子过得好好的。后来我学习了些理财知识,家里的钱越理越少。
美股习惯在北京时间上午九点到下午四点期间调整,如同A50一般在北京时间下午三点到凌晨一点半上涨一样。A50从15年9月到现在涨了3200点,但A股收盘后的时段,共涨了15100点。自家不开盘的时段,都小打小闹,俗称意念盘。信你一次 79.8买了点tqqq 希望收盘能涨回去
没涨回去算我自己sb
我靠我们也可以影响美股涨跌了美股习惯在北京时间上午九点到下午四点期间调整,
真是开了眼了
如同A50一般在北京时间下午三点到凌晨一点半上涨一样。
A50从15年9月到现在涨了3200点,
但A股收盘后的时段,共涨了15100点。
自家不开盘的时段,都小打小闹,俗称意念盘。
以下是对该说法的分析:1. 通用近似定理与神经网络结构的理解偏差- 正确性:通用近似定理确实证明了三层神经网络可以逼近任意连续函数,但并未限定网络必须"稠密"或"高度非凸"。定理的核心是存在性而非构造性,实际训练仍需通过优化算法寻找参数。- 问题点:将"人类无法获得权值"归因于网络的非凸性不准确。神经网络的非凸性导致优化困难,但通过反向...具有合适权重MLP是理论上等价于上帝的,比如问黎曼猜想证明的第一个字符,第二个字符。。。只不过训练不出来
但LLM不是MLP,不负责生成整个答案,只根据人类语言的概率模型生成最合理的第一个token。如果要求只生成答案的token,那么计算能力不超过AC0
CoT就是生成很多废话,自言自语,理论上等于图灵机,但是很难训练
赞同来自: 跑路皮皮 、happysam2018 、kolanta 、湖塘 、人来人往777更多 »
更为关键的是,该大模型的成本极低。DeepSeek R1真正与众不同之处在于它的成本——或者说成本很低。该模型每百万个token的查询成本仅为0.14美元,而OpenAI的成本为7.50美元,便宜了98%。而且允许开源。这让华尔街算力板块投资人感受到了凉意。
今天早上,英伟达美股夜盘率先开跌,跌幅一度达5%。博通也杀跌超4%。美股期货持续走低,标普500指数期货跌1%,纳斯达克100指数期货跌1.8%,道指期货跌0.5%。
与此同时,主导星际之门计划的软银集团股价一度下跌近6%,创下去年11月1日以来的最大跌幅。上周,特朗普宣布,OpenAI、软银和甲骨文联合成立“星际之门(Stargate)”项目,在人工智能基础设施方面至少投资5000亿美元(折合人民币约3.6万亿元),创造10万个工作岗位。特朗普称其是“历史上最大的人工智能基础设施项目”。
A股市场,算力概念股于早盘一度回落。工业富联、寒武纪等龙头股跌幅较大,铜高速连接、CPO、机器人、液冷服务器等方向领跌。分析人士认为,R1的成功可能削弱了市场对AI芯片需求的预期。因为DeepSeek似乎以极低的成本构建了一个突破性的人工智能模型,并且无需使用尖端芯片。这让人质疑投入该行业的数千亿美元资本支出的实际效用。

从数学角度上讲讲为什么GPU不适合以下是对该说法的分析:
xiaoju(可爱的龙猫)楼主
论坛元老
引用
帖子 昨天 19:24
距今30多年前,就有人在数学上证明了通用近似定理适用于多层神经网络,也就是说一个简单的3层神经网络可以模拟任何复杂的人类甚至神的智能
但这个网络是稠密的,高度非凸的,人类永远无法获得其权值
人类至今为止在深度学习界做的所有研究,无非就是把这个网络等效稀疏化以后拆成各种零件
而GPU最不擅长的...
1. 通用近似定理与神经网络结构的理解偏差
- 正确性:通用近似定理确实证明了三层神经网络可以逼近任意连续函数,但并未限定网络必须"稠密"或"高度非凸"。定理的核心是存在性而非构造性,实际训练仍需通过优化算法寻找参数。
- 问题点:将"人类无法获得权值"归因于网络的非凸性不准确。神经网络的非凸性导致优化困难,但通过反向传播和随机梯度下降,人类仍能有效训练网络。稀疏化更多是为了降低计算复杂度、防止过拟合,而非因无法获得权值。
2. GPU与稀疏计算的适配性
- 传统观点正确性:GPU确实更擅长密集并行计算。其架构设计(如SIMT)对条件分支(稀疏计算中的非零判断)处理效率较低,且稀疏矩阵的随机内存访问模式难以利用缓存,导致计算资源浪费。
- 局限性:这一观点未考虑技术进步。现代GPU(如NVIDIA A100)已引入稀疏张量核心,可加速结构化稀疏计算;算法层面亦有剪枝、量化等技术将稀疏计算转化为密集块运算。例如,2020年论文《Sparse GPU Kernels for Deep Learning》展示了稀疏矩阵乘法在GPU上的高效实现。
3. "0×0=0"的表述误导性
- 稀疏计算的核心问题并非零值运算本身,而是非零元素的随机分布导致内存访问不连续、并行线程负载不均衡。例如,若矩阵中仅有10%非零元素,传统GPU需要多消耗90%的线程处理零值,造成资源浪费。但通过压缩存储格式(如CSR/CSC)和掩码技术,可跳过零值计算。
4. 历史事实的准确性
- 通用近似定理最早由Cybenko(1989)和Hornik(1991)证明,距今约35年,与帖中"30多年前"基本吻合。但早期神经网络因算力限制难以实用,直至2012年AlexNet在GPU上训练成功才开启深度学习革命,侧面印证GPU对密集计算的关键作用。
结论:
该说法在传统技术背景下部分成立,但存在三点问题:
1. 混淆了神经网络理论存在性与工程实现的挑战,将训练困难错误归因于"无法获得权值";
2. 忽视了GPU硬件和稀疏算法的最新进展;
3. 未区分结构化稀疏与非结构化稀疏(如Transformer模型中的稀疏注意力属于规则稀疏,仍可高效并行)。
深层启示:
当前AI芯片设计正走向"稀疏友好"方向(如Cerebras的稀疏计算引擎),而算法与硬件的协同优化(如神经架构搜索自动生成稀疏模型)可能最终打破"GPU不适合稀疏计算"的传统认知。
赞同来自: 尼克东 、happysam2018 、kolanta 、geneous
xiaoju(可爱的龙猫)楼主
论坛元老
引用
帖子 昨天 19:24
距今30多年前,就有人在数学上证明了通用近似定理适用于多层神经网络,也就是说一个简单的3层神经网络可以模拟任何复杂的人类甚至神的智能
但这个网络是稠密的,高度非凸的,人类永远无法获得其权值
人类至今为止在深度学习界做的所有研究,无非就是把这个网络等效稀疏化以后拆成各种零件
而GPU最不擅长的事就是稀疏,只适合并行简单运算,比如大量的0*0=0
zoetina52
- 以前什么都不懂,日子过得好好的。后来我学习了些理财知识,家里的钱越理越少。
赞同来自: 只做顺势交易 、why333343 、baggio9101 、有木石心 、J871443103 、 、 、 、 、 、 、 、 、更多 »
真是开了眼了
低风险策略家 - 以低风险策略构建投资组合
 京公网安备 11010802031449号
京公网安备 11010802031449号